Stacking of multiply-imputed datasets so that single analyses can be done (Morris et al. (2015))
Optimum unsupervised nonlinear transformations
Redundancy analysis
Sparse principal components
High-level statistical reporting functions in the qreport package (dataOverview, missChk, vClus)
The optimum nonlinear transformations are determined form the transace function in the Hmisc package, which uses the ACE algorithm. Nonlinear transformations, redundancy analysis, and sparse PCs are all done on a tall stacked multiply-imputed dataset.
24.1 Descriptive Statistics
Click on the tabs to see the different kinds of variables. Hover over spike histograms to see frequencies and details about binning.
Code
getHdata(bacteremia)d <- bacteremia# Load javascript dependencies for interactive spike histogramssparkline::sparkline(0)
Plot of the degree of symmetry of the distribution of a variable (value of 1.0 is most symmetric) vs. the number of distinct values of the variable. Hover over a point to see the variable name and detailed characteristics.
Code
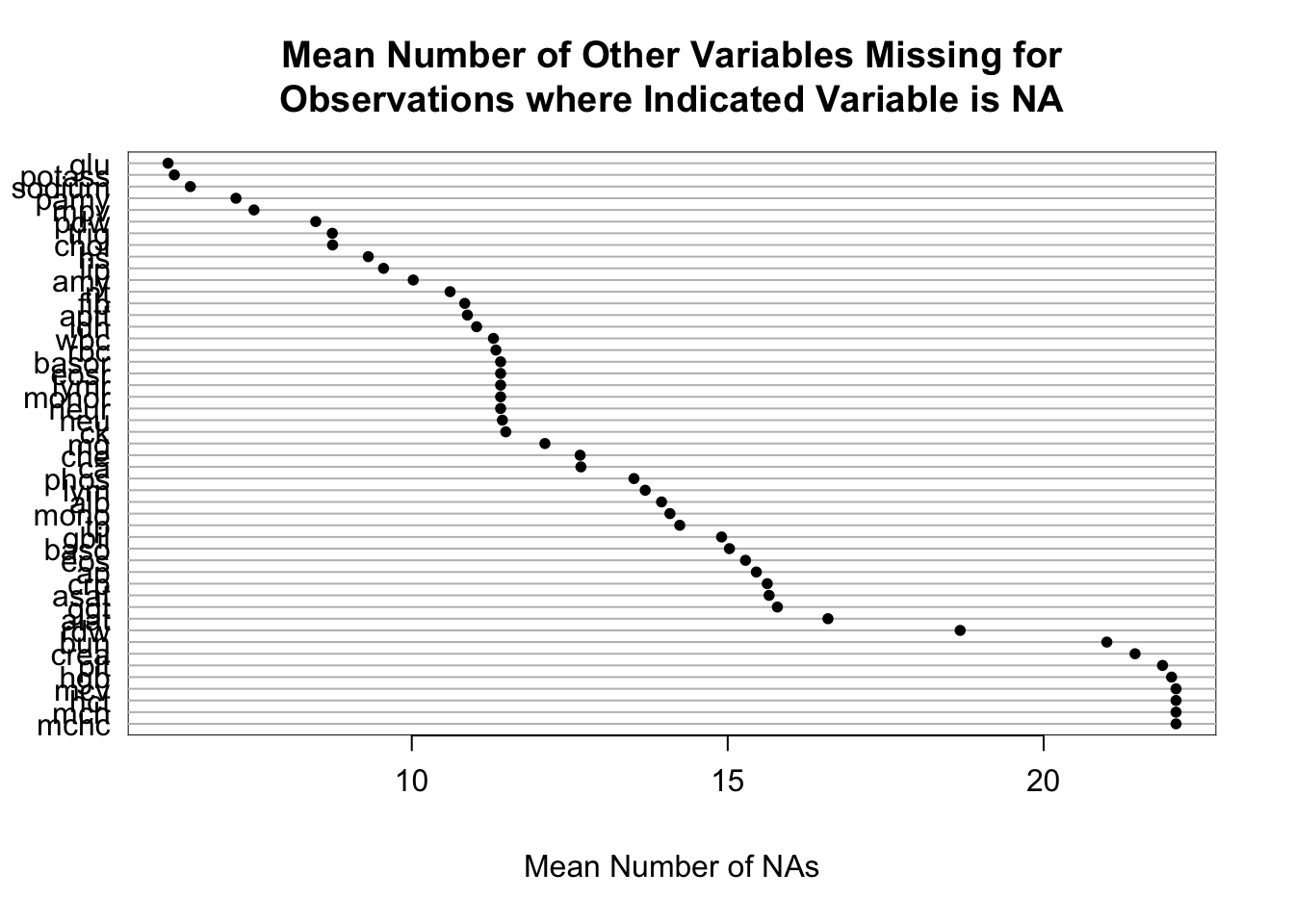
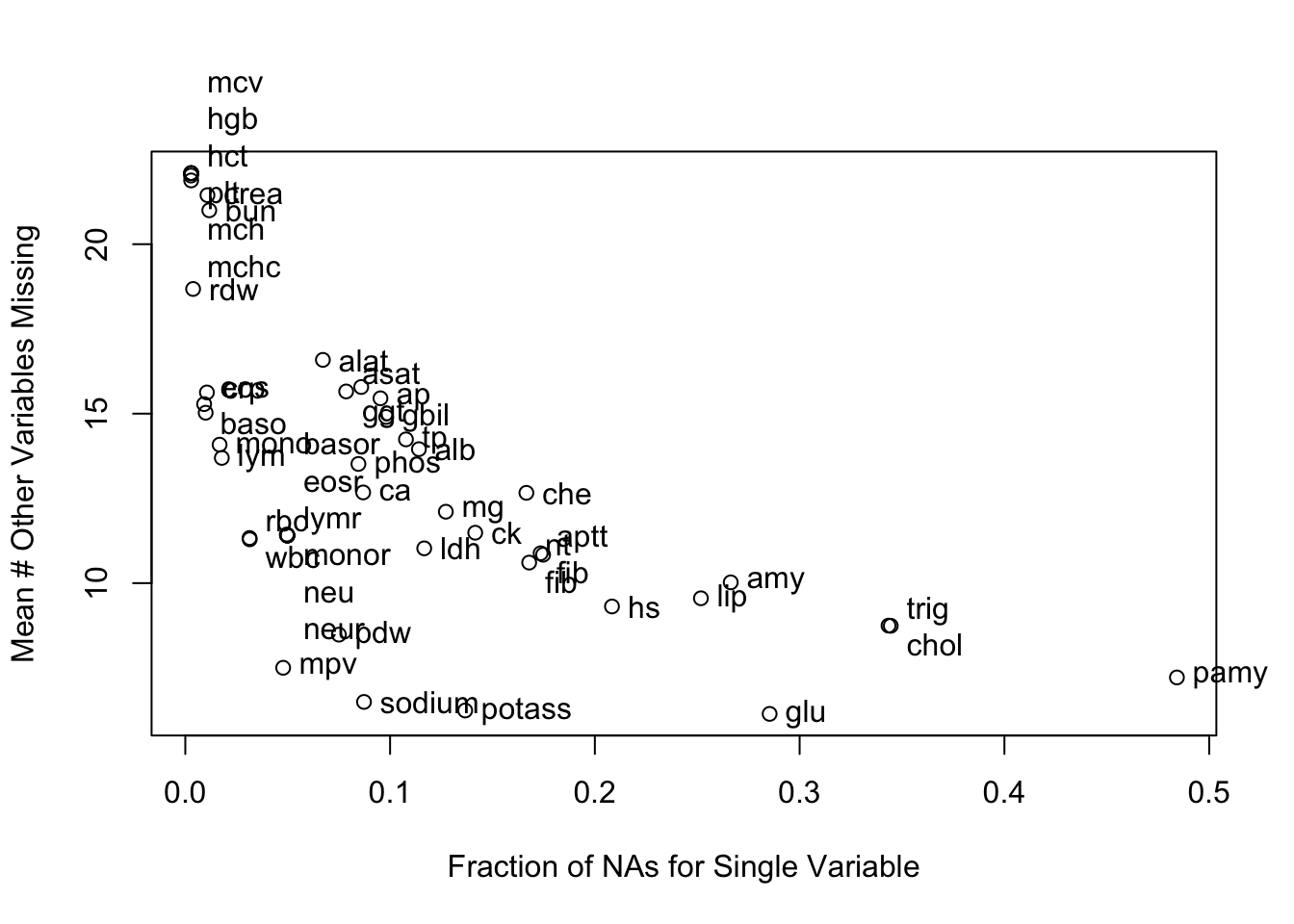
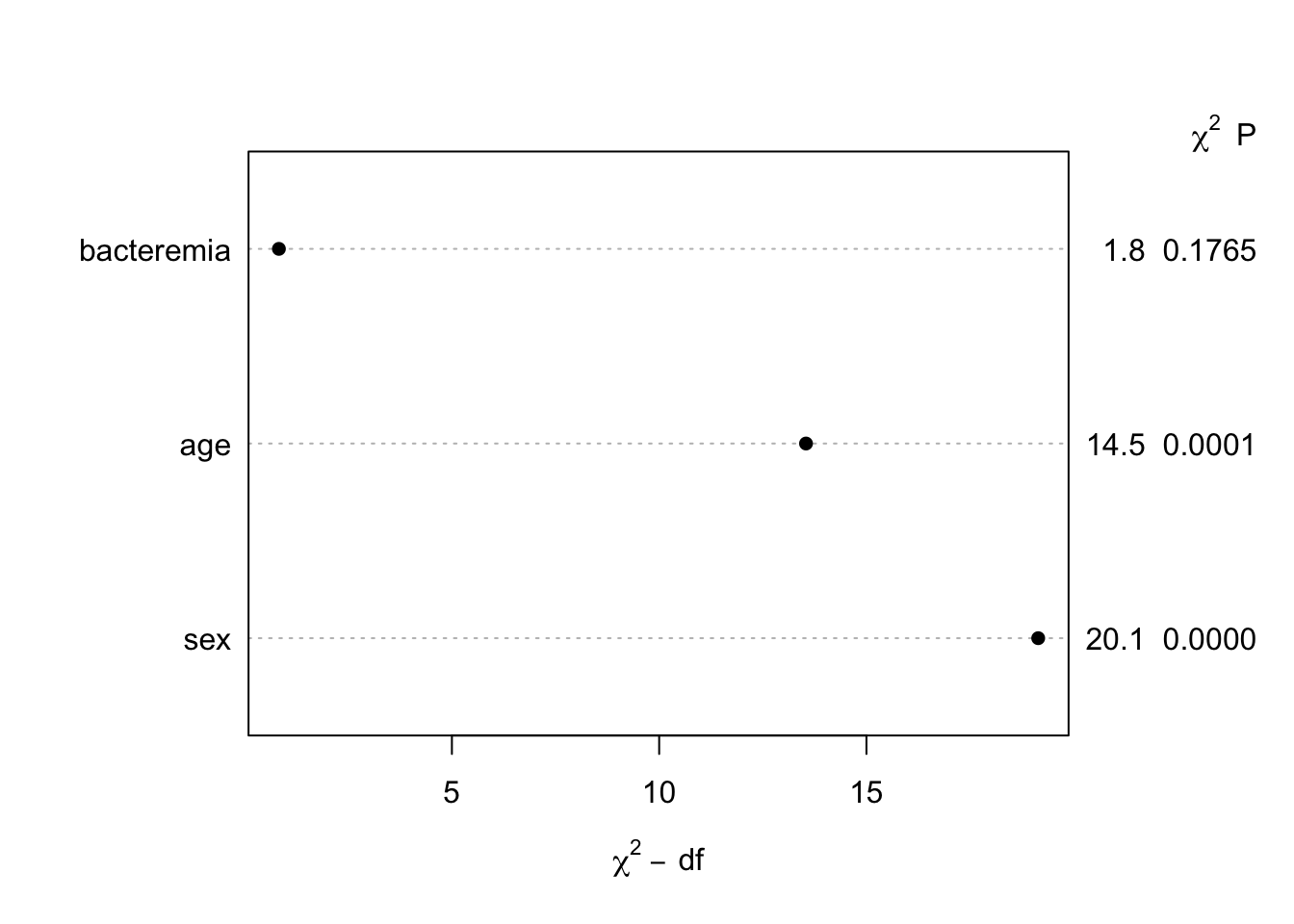
missChk(d, prednmiss=TRUE, omitpred='id')
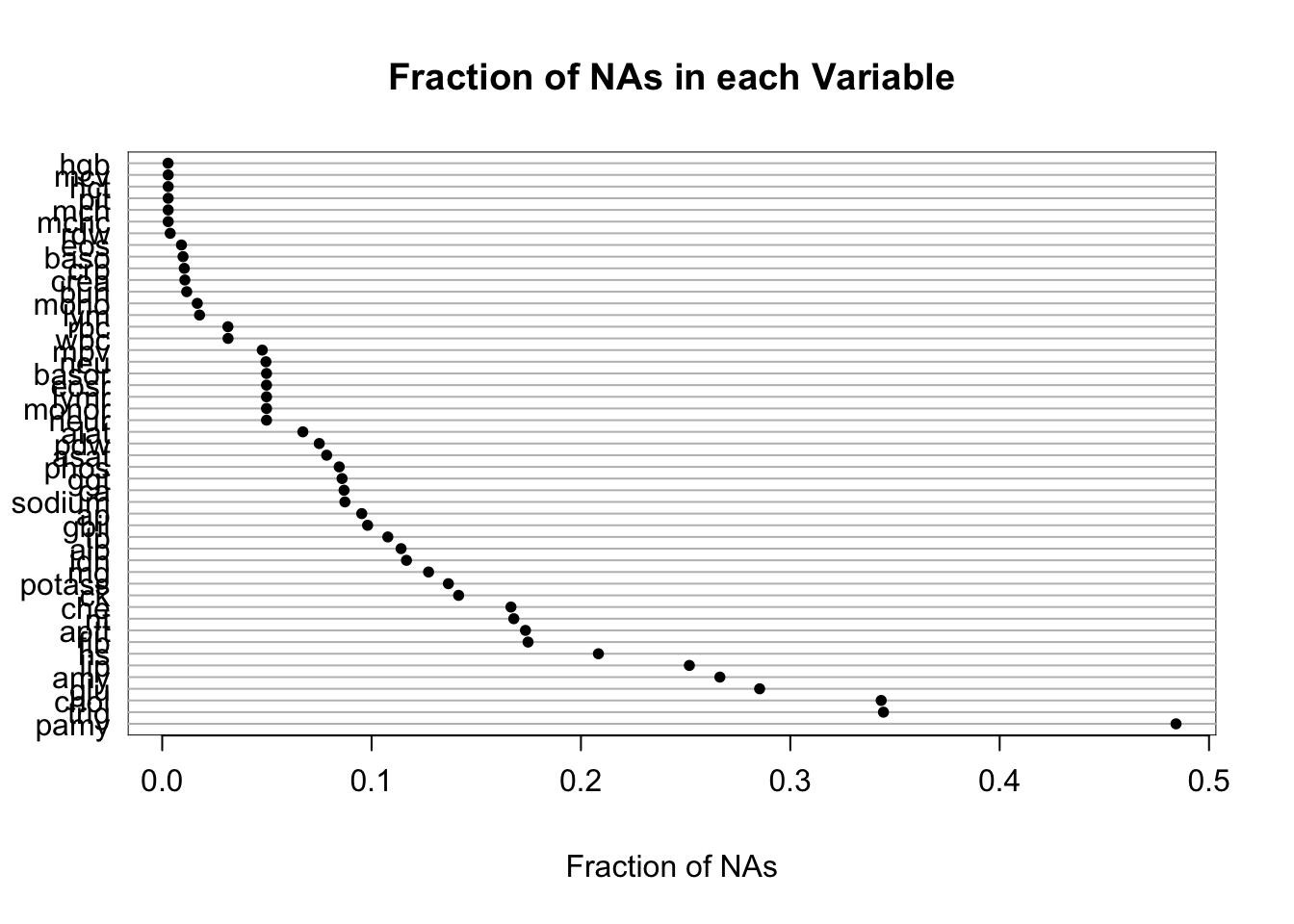
4 variables have no NAs and 49 variables have NAs
d has 14691 observations (3979 complete) and 53 variables (4 complete)
Number of NAs
Minimum
Maximum
Mean
Per variable
0
7114
1354.5
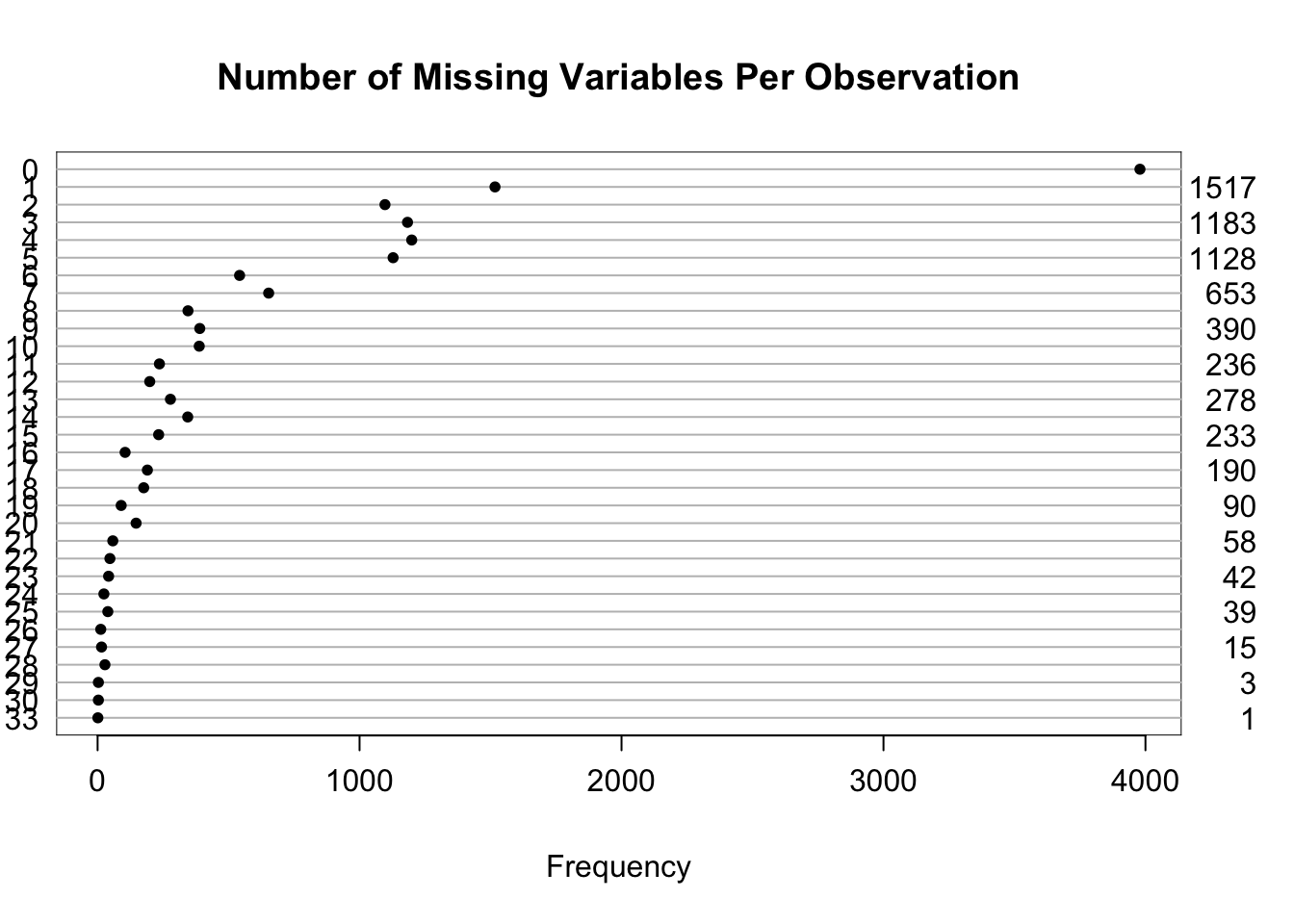
Per observation
0
33
4.9
Frequency distribution of number of NAs per variable
0
41
42
56
135
146
155
159
172
246
262
461
462
702
728
732
987
1102
1154
1242
1262
1276
1282
1400
1441
1583
1676
1714
1869
2008
2080
2447
2467
2549
2567
3061
3699
3913
4192
5045
5061
7114
4
1
5
1
1
1
1
1
1
1
1
1
1
1
1
5
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Frequency distribution of number of incomplete variables per observation
From the last tab, age and sex are predictors of the number of missing variables per observation, but the associations are very weak.
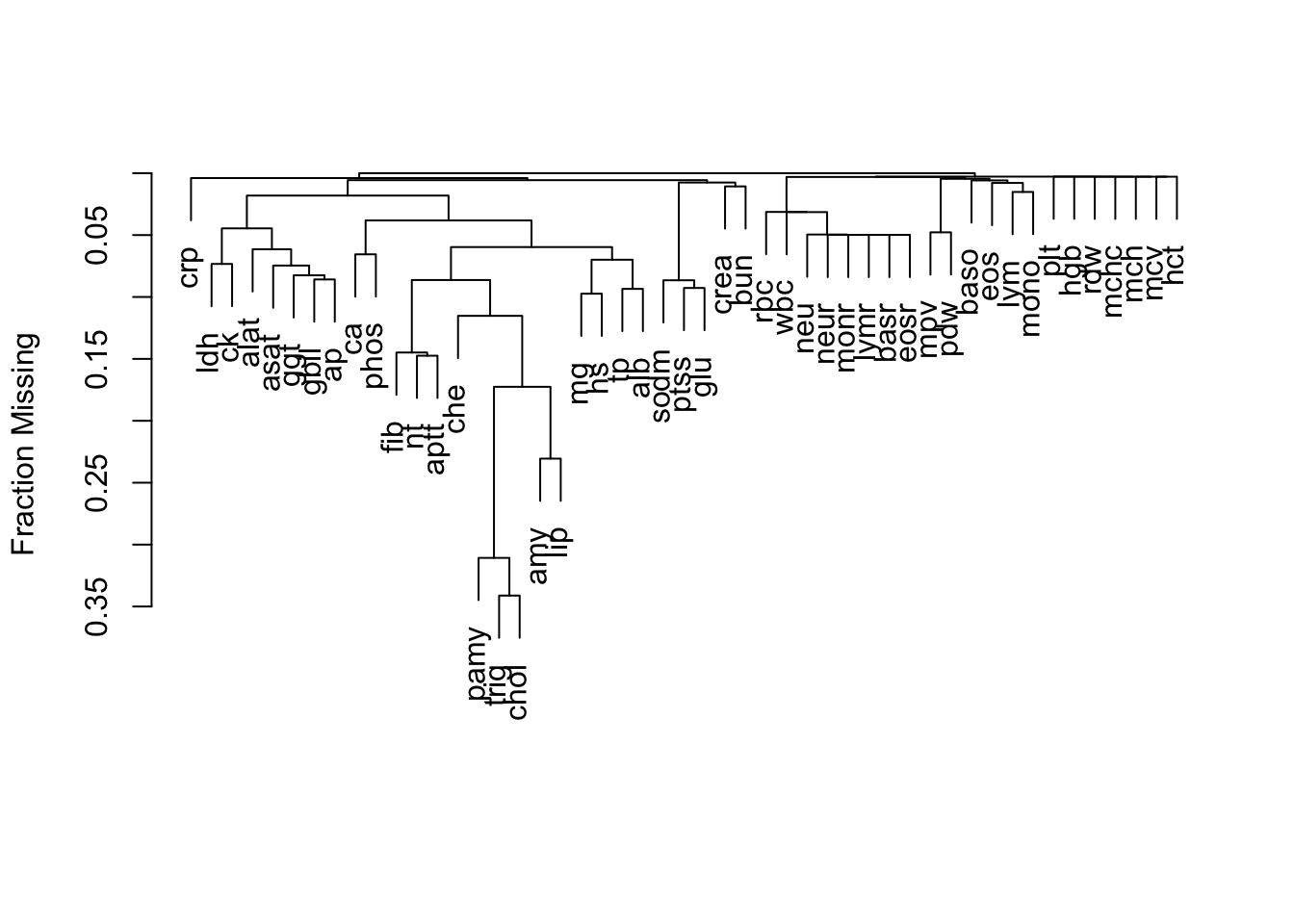
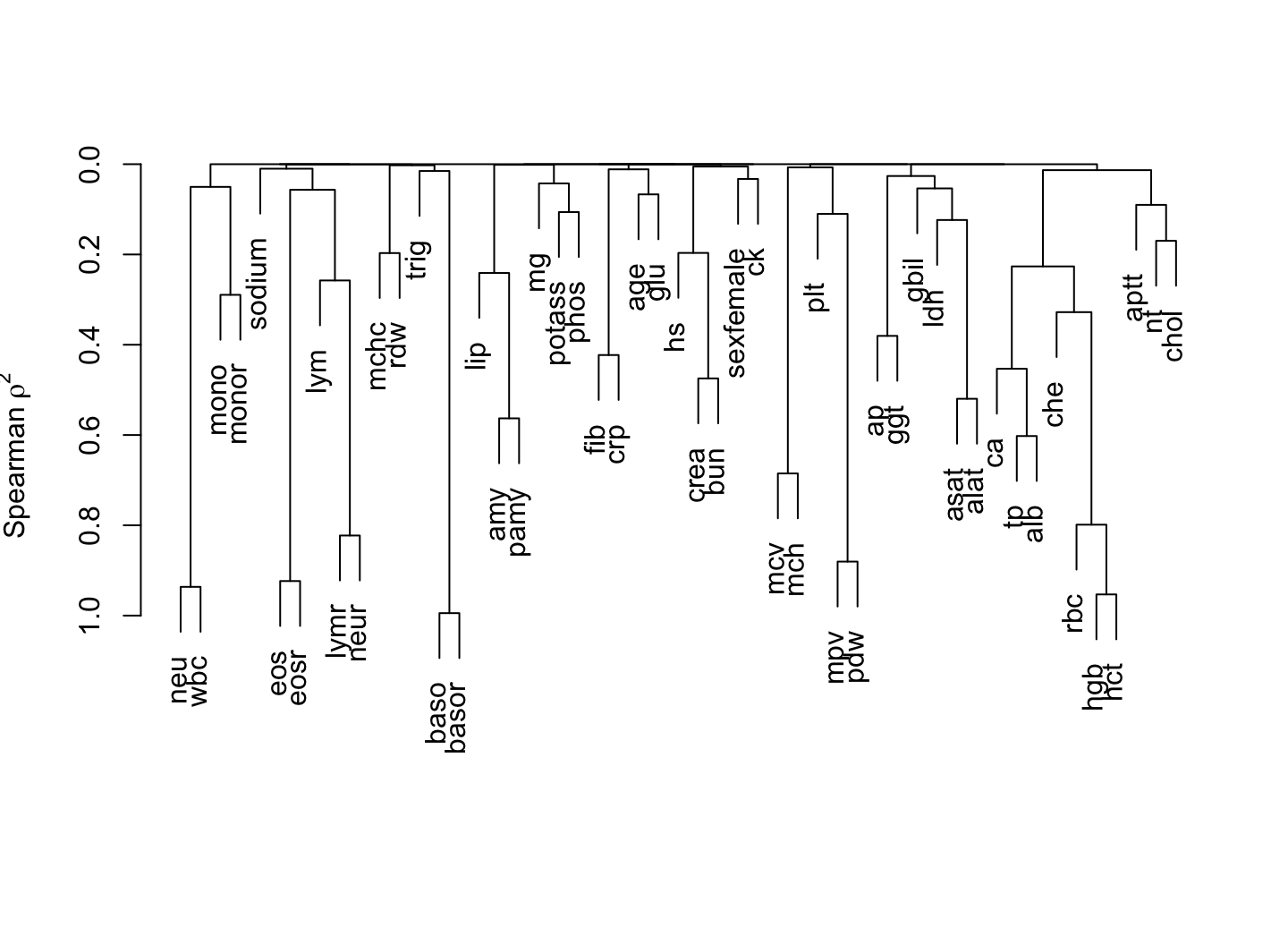
24.2 Variable Clustering
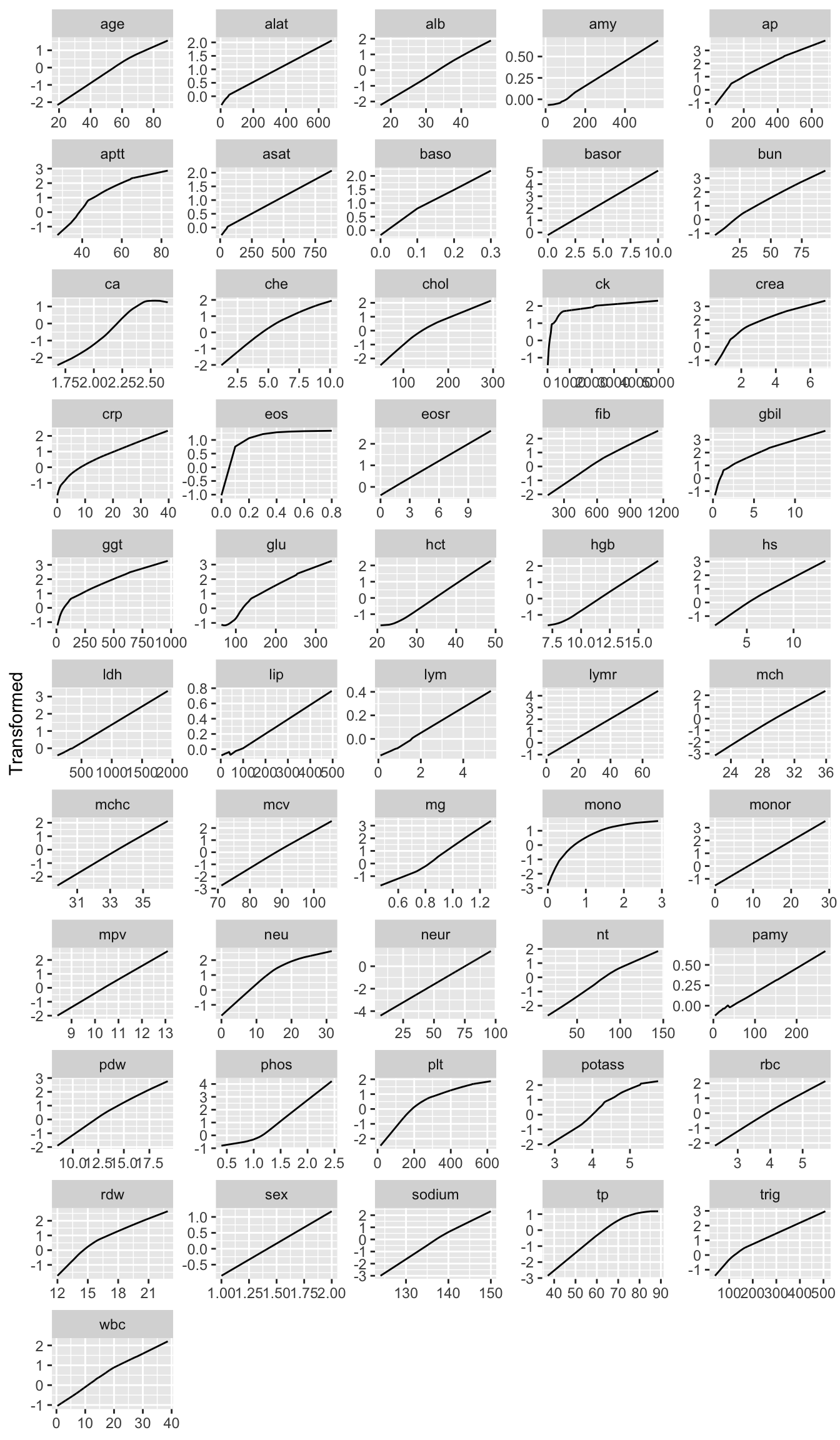
The R Hmisc package transace function, which uses the ACE (alternating conditional expectation) algorithm, is used to transform all the continuous variables. Transformations use nonparametric smoothers and are allowed to be non-monotonic. Transformation solutions maximize the \(R^2\) which with each variable can be predicted from the other variables, optimally transformed. The transformed variables are used in redundancy analysis and sparse principal components analysis. Bacteremia and subject id are not used in these unsupervised learning procedures.
To be more efficient, use multiple (5) imputations with predictive mean matching so that vClus will stack all the filled-in datasets before running the redundancy and PCA which are run on the single tall dataset, which contains no NAs. The correlation matrix and varclus results are already efficient because they use pairwise deletion of NAs.
Because transformed variables are passed to the redundancy analysis, variables are not expanded into splines in that analysis (see nk=0 below).
Here is the order in which vClus does things:
clustering with pairwise NA deletion
complete datasets using aregImpute output, stack them, use stacked data for all that follows
transace
redun
sparce PCA
Code
n <-setdiff(names(d), 'id')n[n =='baso'] <-'I(baso)'f <-as.formula(paste('~', paste(n, collapse='+')))if(!file.exists('bacteremia-aregimpute.rds')) {set.seed(1) a <-aregImpute(f, data=d, n.impute=5)saveRDS(a, 'bacteremia-aregimpute.rds') } else a <-readRDS('bacteremia-aregimpute.rds')
1
all variables other than id
2
force baso to be linear in multiple imputation because of ties
3
aregImpute ran about 15 minutes when
4
so that multiple imputations reproduce
Code
v <-vClus(d, fracmiss=0.8, corrmatrix=TRUE,trans=TRUE, redundancy=TRUE, spc=TRUE,exclude =~ id + bacteremia,imputed=a,redunargs=list(nk=0),spcargs=list(k=20, sw=TRUE, nvmax=5), # sparse PCA 5mtransacefile='bacteremia-transace.rds',spcfile='bacteremia-spc.rds') # uses previous run if no inputs changed
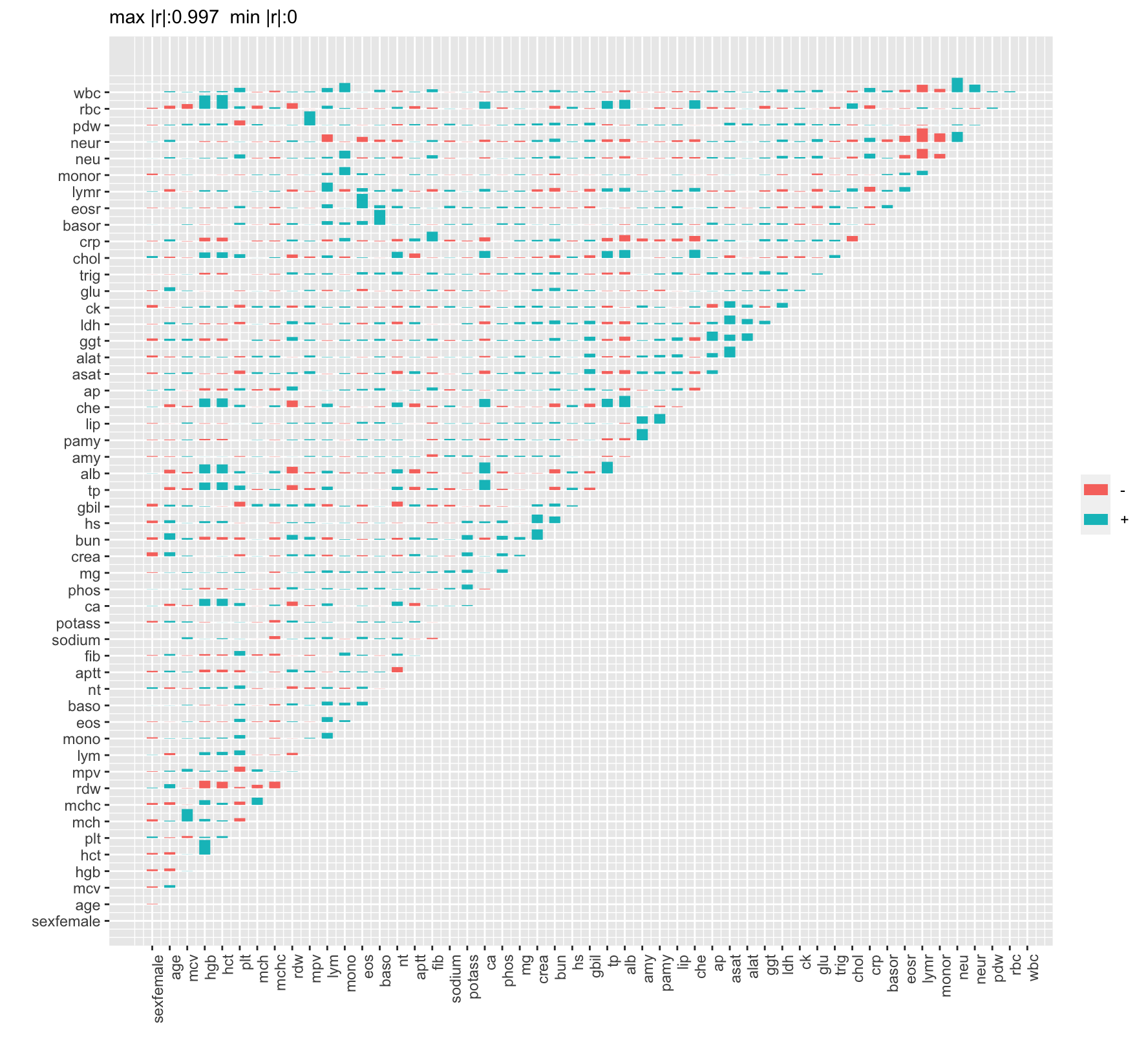
Figure 24.2: Spearman rank correlation matrix. Positive correlations are blue and negative are red.
Re-run because of changes in the following objects: args
Redundancy Analysis
n: 73455 p: 51 nk: 0
Number of NAs: 0
Transformation of target variables forced to be linear
R-squared cutoff: 0.9 Type: ordinary
R^2 with which each variable can be predicted from all other variables:
sex age mcv hgb hct plt mch mchc rdw mpv lym mono
0.190 0.281 0.995 0.991 0.992 0.503 0.996 0.984 0.505 0.892 0.813 0.625
eos baso nt aptt fib sodium potass ca phos mg crea bun
0.294 0.538 0.375 0.242 0.652 0.256 0.237 0.605 0.343 0.214 0.651 0.717
hs gbil tp alb amy pamy lip che ap asat alat ggt
0.432 0.394 0.747 0.838 0.811 0.524 0.708 0.664 0.558 0.802 0.686 0.539
ldh ck glu trig chol crp basor eosr lymr monor neu neur
0.648 0.269 0.146 0.275 0.545 0.658 0.976 0.994 0.999 0.997 0.829 1.000
pdw rbc wbc
0.893 0.962 0.873
Rendundant variables:
neur mch hct hgb
Predicted from variables:
sex age mcv plt mchc rdw mpv lym mono eos baso nt aptt fib sodium potass ca
phos mg crea bun hs gbil tp alb amy pamy lip che ap asat alat ggt ldh ck
glu trig chol crp basor eosr lymr monor neu pdw rbc wbc
Variable Deleted R^2 R^2 after later deletions
1 neur 1.000 1 1 1
2 mch 0.996 0.996 0.996
3 hct 0.992 0.958
4 hgb 0.949
Code
htmlVerbatim(v$transace)
Transformations Using Alternating Conditional Expectation
~sex + age + mcv + hgb + hct + plt + mch + mchc + rdw + mpv +
lym + mono + eos + baso + nt + aptt + fib + sodium + potass +
ca + phos + mg + crea + bun + hs + gbil + tp + alb + amy +
pamy + lip + che + ap + asat + alat + ggt + ldh + ck + glu +
trig + chol + crp + basor + eosr + lymr + monor + neu + neur +
pdw + rbc + wbc
n= 73455
Transformations:
sex age mcv hgb hct plt mch
categorical general general general general general general
mchc rdw mpv lym mono eos baso
general general general general general general general
nt aptt fib sodium potass ca phos
general general general general general general general
mg crea bun hs gbil tp alb
general general general general general general general
amy pamy lip che ap asat alat
general general general general general general general
ggt ldh ck glu trig chol crp
general general general general general general general
basor eosr lymr monor neu neur pdw
general general general general general general general
rbc wbc
general general
R-squared achieved in predicting each variable:
sex age mcv hgb hct plt mch mchc rdw mpv lym mono
0.275 0.405 0.995 0.992 0.992 0.547 0.996 0.983 0.552 0.897 0.844 0.870
eos baso nt aptt fib sodium potass ca phos mg crea bun
0.904 0.605 0.384 0.275 0.663 0.288 0.274 0.619 0.412 0.237 0.675 0.730
hs gbil tp alb amy pamy lip che ap asat alat ggt
0.486 0.429 0.773 0.850 0.814 0.532 0.714 0.677 0.583 0.811 0.693 0.609
ldh ck glu trig chol crp basor eosr lymr monor neu neur
0.660 0.431 0.183 0.348 0.564 0.678 0.976 0.994 0.999 0.997 0.919 1.000
pdw rbc wbc
0.899 0.978 0.899
Code
saveRDS(v, '/tmp/v.rds')
Code
ggplot(v$transace, nrow=12)
Code
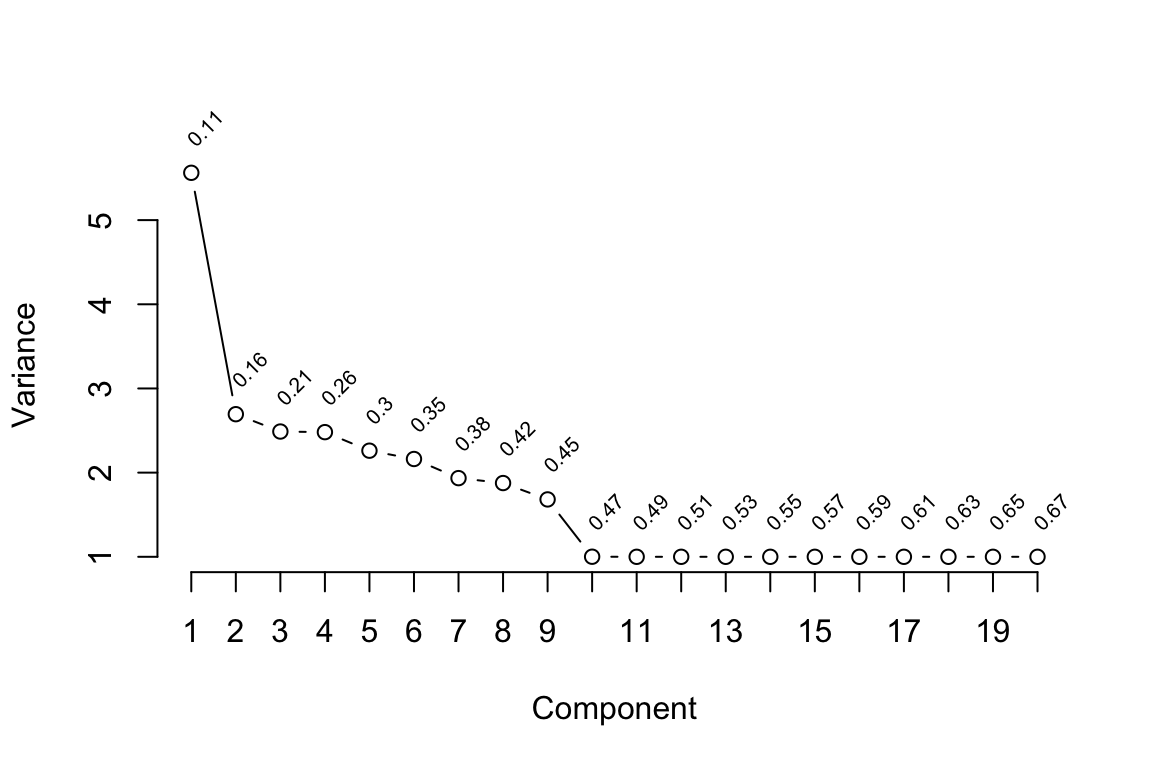
p <- v$princmp# Print and plot sparse PC resultsprint(p)
Sparse Principal Components Analysis
Stepwise Approximations to PCs With Cumulative R^2
PC 1
alb (0.767) + hct (0.943) + chol (0.96) + che (0.969) + ca (0.979)
PC 2
neur (0.849) + neu (0.974) + lymr (0.989) + wbc (0.998) + monor (1)
PC 3
crea (0.811) + hs (0.908) + phos (0.961) + bun (0.996) + ca (0.999)
PC 4
asat (0.917) + ldh (0.959) + alat (1)
PC 5
amy (0.935) + pamy (0.957) + lip (1)
Code
plot(p)
Code
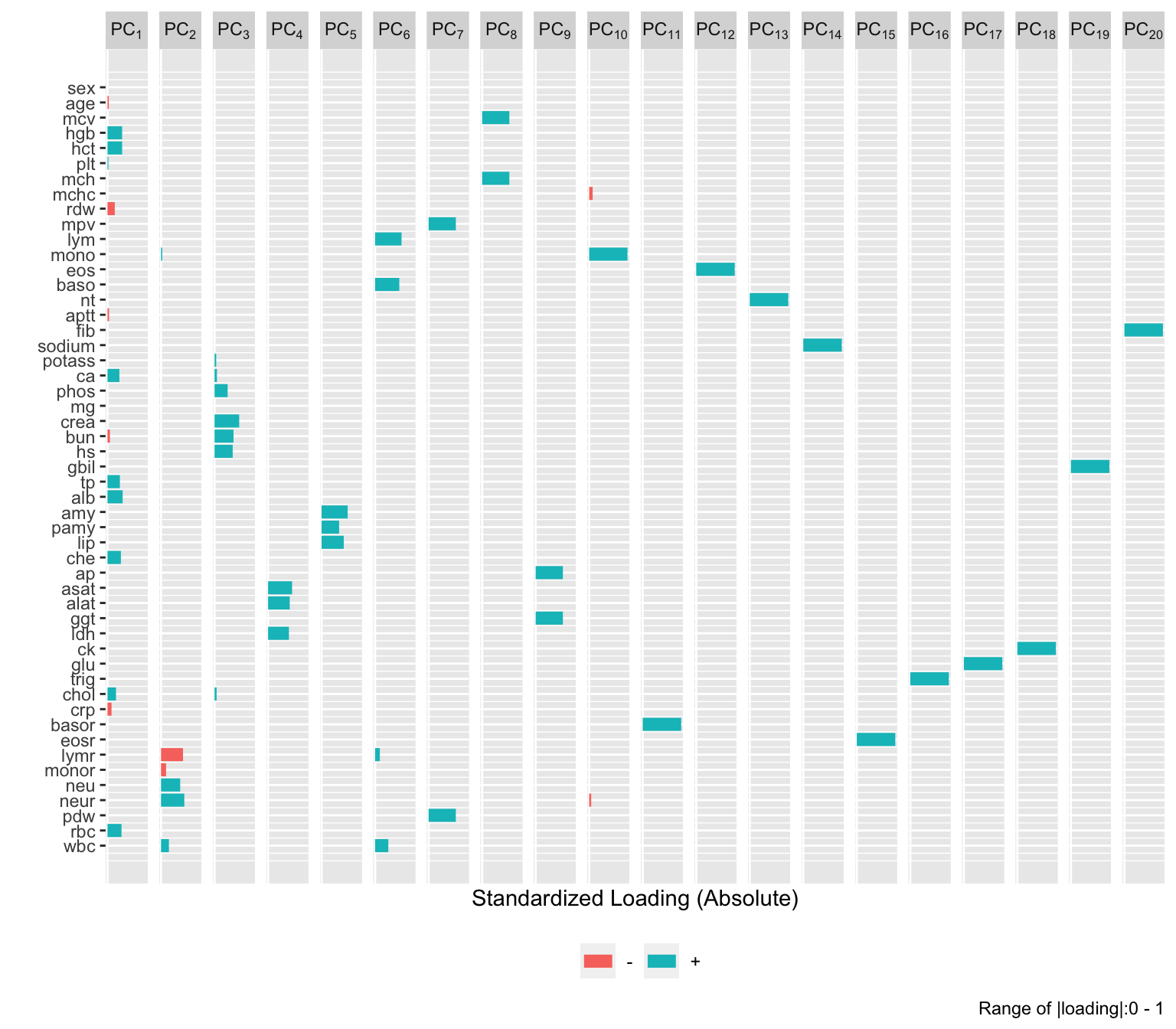
plot(v$p, 'loadings', nrow=1)
Morris, T. P., White, I. R., Carpenter, J. R., Stanworth, S. J., & Royston, P. (2015). Combining fractional polynomial model building with multiple imputation: T. P. Morriset Al . Statist. Med., 34(25), 3298–3317. https://doi.org/10.1002/sim.6553
Source Code
```{r include=FALSE}require(Hmisc)require(ggplot2)options(qproject='rms', prType='html')require(qreport)getRs('qbookfun.r')hookaddcap()knitr::set_alias(w = 'fig.width', h = 'fig.height', cap = 'fig.cap', scap ='fig.scap')```# Bacteremia: Case Study in Nonlinear Data Reduction with Imputation {#sec-bacteremia}**Data*** Study of 14,691 patients to analyze risk of bacteremia on the basis of many highly standardized blood analysis parameters* Vienna General Hospital 2006-2010* [Ratzinger et al](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0106765)* Data modified for public use by [Heinze](https://zenodo.org/record/7554815#.ZF-dztLMK-Y) and available for easy use in R at [hbiostat.org/data](https://hbiostat.org/data)**Methods Illustrated*** Multiple imputation* Variable clustering with pairwise deletion of `NA`s* Stacking of multiply-imputed datasets so that single analyses can be done (@mor15com)* Optimum unsupervised nonlinear transformations* Redundancy analysis* Sparse principal components* High-level statistical reporting functions in the `qreport` package (`dataOverview, missChk, vClus`)The optimum nonlinear transformations are determined form the `transace` function in the `Hmisc` package, which uses the [ACE algorithm](https://en.wikipedia.org/wiki/Alternating_conditional_expectations). Nonlinear transformations, redundancy analysis, and sparse PCs are all done on a tall stacked multiply-imputed dataset.## Descriptive Statistics[Click on the tabs to see the different kinds of variables. Hover over spike histograms to see frequencies and details about binning.]{.aside}```{r results='asis'}getHdata(bacteremia)d <- bacteremia# Load javascript dependencies for interactive spike histogramssparkline::sparkline(0)maketabs(print(describe(d), 'both'), cwidth='column-screen-inset-shaded')``````{r results='asis'}dataOverview(d, id = ~ id)missChk(d, prednmiss=TRUE, omitpred='id')```From the last tab, age and sex are predictors of the number of missing variables per observation, but the associations are very weak.## Variable ClusteringThe R `Hmisc` package `transace` function, which uses the ACE (alternating conditional expectation) algorithm, is used to transform all the continuous variables. Transformations use nonparametric smoothers and are allowed to be non-monotonic. Transformation solutions maximize the $R^2$ which with each variable can be predicted from the other variables, optimally transformed. The transformed variables are used in redundancy analysis and sparse principal components analysis. Bacteremia and subject `id` are not used in these unsupervised learning procedures.To be more efficient, use multiple (5) imputations with predictive mean matching so that `vClus` will stack all the filled-in datasets before running the redundancy and PCA which are run on the single tall dataset, which contains no `NA`s. The correlation matrix and `varclus` results are already efficient because they use pairwise deletion of `NA`s.Because transformed variables are passed to the redundancy analysis, variables are not expanded into splines in that analysis (see `nk=0` below).Here is the order in which `vClus` does things:* clustering with pairwise `NA` deletion* complete datasets using `aregImpute` output, stack them, use stacked data for all that follows* `transace`* `redun`* sparce PCA```{r}n <-setdiff(names(d), 'id') #<1>n[n =='baso'] <-'I(baso)'#<2>f <-as.formula(paste('~', paste(n, collapse='+')))if(!file.exists('bacteremia-aregimpute.rds')) {set.seed(1) #<4> a <-aregImpute(f, data=d, n.impute=5) #<3>saveRDS(a, 'bacteremia-aregimpute.rds') } else a <-readRDS('bacteremia-aregimpute.rds')```1. all variables other than `id`2. force `baso` to be linear in multiple imputation because of ties3. `aregImpute` ran about 15 minutes when4. so that multiple imputations reproduce```{r results='asis'}v <- vClus(d, fracmiss=0.8, corrmatrix=TRUE, trans=TRUE, redundancy=TRUE, spc=TRUE, exclude = ~ id + bacteremia, imputed=a, redunargs=list(nk=0), spcargs=list(k=20, sw=TRUE, nvmax=5), # sparse PCA 5m transacefile='bacteremia-transace.rds', spcfile='bacteremia-spc.rds') # uses previous run if no inputs changedhtmlVerbatim(v$transace)saveRDS(v, '/tmp/v.rds')``````{r}#| fig-height: 12#| fig-width: 7ggplot(v$transace, nrow=12)``````{r}#| fig-height: 4#| fig-width: 6p <- v$princmp# Print and plot sparse PC resultsprint(p)plot(p)``````{r}#| fig-height: 7#| fig-width: 8#| column: screen-rightplot(v$p, 'loadings', nrow=1)``````{r echo=FALSE}saveCap('24')```