Code
f <- lrm(y ~ sex + race + rcs(age,5) + rcs(weight,5) +
rcs(height,5) + rcs(blood.pressure,5))
plot(anova(f))Scientific Big Picture
Modeling Strategy in a Nutshell
There are many choices to be made when deciding upon a global modeling strategy, including choice between
Motivating examples:
# Overfitting a flat relationship
require(rms)
set.seed(1)
x <- runif(1000)
y <- runif(1000, -0.5, 0.5)
dd <- datadist(x, y); options(datadist='dd')
par(mfrow=c(2,2), mar=c(2, 2, 3, 0.5))
pp <- function(actual) {
yhat <- predict(f, data.frame(x=xs))
yreal <- actual(xs)
plot(0, 0, xlim=c(0,1),
ylim=range(c(quantile(y, c(0.1, 0.9)), yhat,
yreal)),
type='n', axes=FALSE)
axis(1, labels=FALSE); axis(2, labels=FALSE)
lines(xs, yreal)
lines(xs, yhat, col='blue')
}
f <- ols(y ~ rcs(x, 5))
xs <- seq(0, 1, length=150)
pp(function(x) 0*x)
title('Mild Error:\nOverfitting a Flat Relationship',
cex=0.5)
y <- x + runif(1000, -0.5, 0.5)
f <- ols(y ~ rcs(x, 5))
pp(function(x) x)
title('Mild Error:\nOverfitting a Linear Relationship',
cex=0.5)
y <- x^4 + runif(1000, -1, 1)
f <- ols(y ~ x)
pp(function(x) x^4)
title('Serious Error:\nUnderfitting a Steep Relationship',
cex=0.5)
y <- - (x - 0.5) ^ 2 + runif(1000, -0.2, 0.2)
f <- ols(y ~ x)
pp(function(x) - (x - 0.5) ^ 2)
title('Tragic Error:\nMonotonic Fit to\nNon-Monotonic Relationship',
cex=0.5)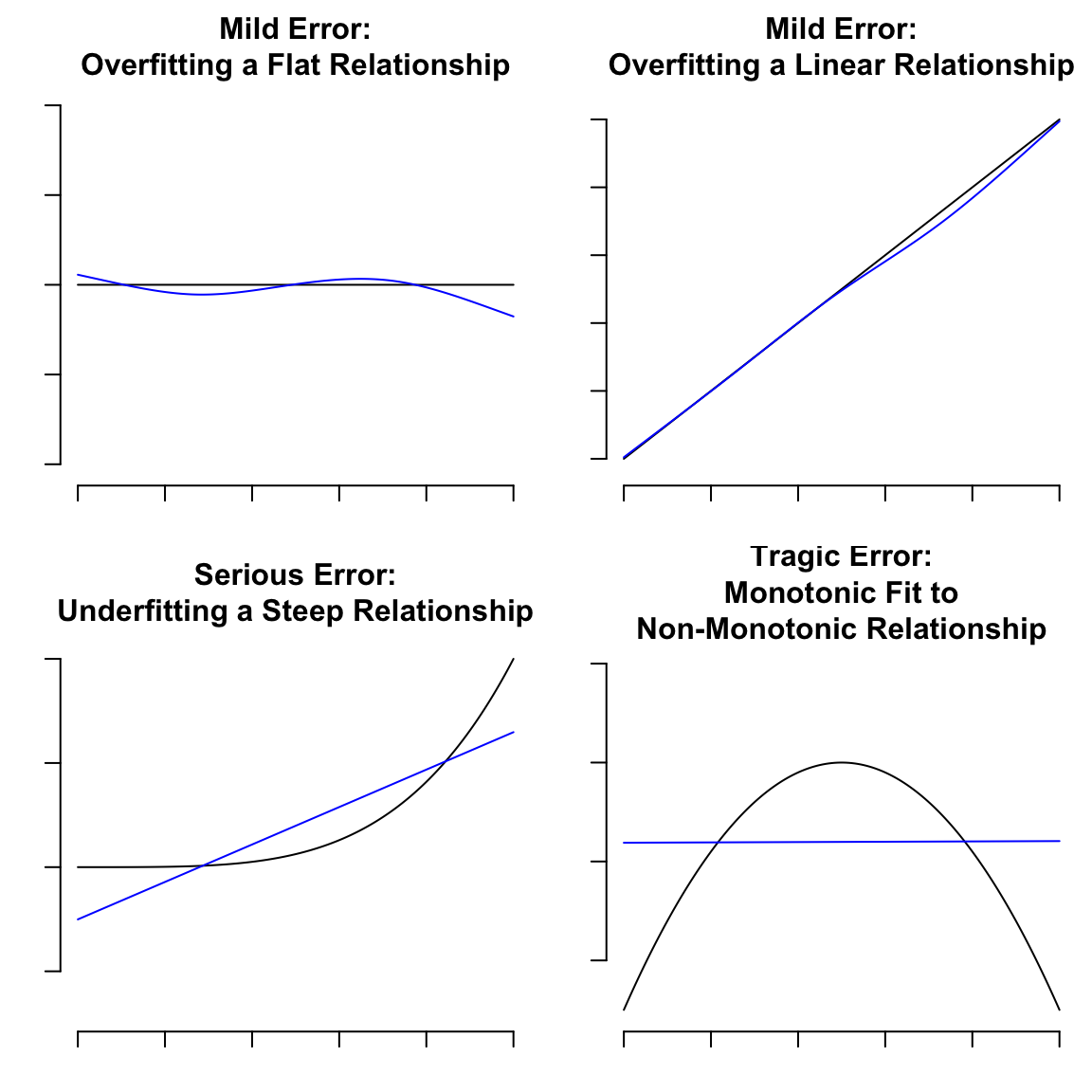
| Categorical predictor with \(k\) levels | Collapse less frequent categories into “other” |
| Continuous predictor represented as \(k\)-knot restricted cubic spline | Reduce \(k\) to a number as low as 3, or 0 (linear) |
When the effective sample size available is sufficiently large so that a saturated main effects model may be fitted, a good approach to gauging predictive potential is the following.
Commands in the rms package can be used to plot only what is needed. Here is an example for a logistic model.
f <- lrm(y ~ sex + race + rcs(age,5) + rcs(weight,5) +
rcs(height,5) + rcs(blood.pressure,5))
plot(anova(f))When collinearities or confounding are not problematic, a quicker approach based on pairwise measures of association can be useful. This approach will not have numerical problems (e.g., singular covariance matrix) and is based on:
1 This test statistic does not inform the analyst of which groups are different from one another.
Allocating d.f. based on partial tests of association or sorting \(\rho^2\) is a fair procedure because
Initial simulations show the procedure to be conservative. Note that one can move from simpler to more complex models but not the other way round
2 Lockhart et al. (2013) provide an example with \(n=100\) and 10 orthogonal predictors where all true \(\beta\)s are zero. The test statistic for the first variable to enter has type I assertion probability of 0.39 when the nominal \(\alpha\) is set to 0.05.
- The degree of correlation between the predictor variables affected the frequency with which authentic predictor variables found their way into the final model.
- The number of candidate predictor variables affected the number of noise variables that gained entry to the model.
- The size of the sample was of little practical importance in determining the number of authentic variables contained in the final model.
- The population multiple coefficient of determination could be faithfully estimated by adopting a statistic that is adjusted by the total number of candidate predictor variables rather than the number of variables in the final model.
Simulation experiment, true \(\sigma^{2} = 6.25\), 8 candidate variables, 4 of them related to \(Y\) in the population. Select best model using all possible subsets regression to maximize \(R^{2}_{adj}\) (all possible subsets is not usually recommended but gives variable selection more of a chance to work in this context).
Note: The audio was made using stepAIC with collinearities in predictors. The code below allows for several options. Here we use all possible subsets of predictors and force predictors to be uncorrelated, which is the easiest case for variable selection.
require(MASS) # provides stepAIC function
require(leaps) # provides regsubsets function
sim <- function(n, sigma=2.5, method=c('stepaic', 'leaps'),
pr=FALSE, prcor=FALSE, dataonly=FALSE) {
method <- match.arg(method)
if(uncorrelated) {
x1 <- rnorm(n)
x2 <- rnorm(n)
x3 <- rnorm(n)
x4 <- rnorm(n)
x5 <- rnorm(n)
x6 <- rnorm(n)
x7 <- rnorm(n)
x8 <- rnorm(n)
}
else {
x1 <- rnorm(n)
x2 <- x1 + 2.0 * rnorm(n) # was + 0.5 * rnorm(n)
x3 <- rnorm(n)
x4 <- x3 + 1.5 * rnorm(n)
x5 <- x1 + rnorm(n)/1.3
x6 <- x2 + 2.25 * rnorm(n) # was rnorm(n)/1.3
x7 <- x3 + x4 + 2.5 * rnorm(n) # was + rnorm(n)
x8 <- x7 + 4.0 * rnorm(n) # was + 0.5 * rnorm(n)
}
z <- cbind(x1,x2,x3,x4,x5,x6,x7,x8)
if(prcor) return(round(cor(z), 2))
lp <- x1 + x2 + .5*x3 + .4*x7
y <- lp + sigma*rnorm(n)
if(dataonly) return(list(x=z, y=y))
if(method == 'leaps') {
s <- summary(regsubsets(z, y))
best <- which.max(s$adjr2)
xvars <- s$which[best, -1] # remove intercept
ssr <- s$rss[best]
p <- sum(xvars)
xs <- if(p == 0) 'none' else paste((1 : 8)[xvars], collapse='')
if(pr) print(xs)
ssesw <- (n - 1) * var(y) - ssr
s2s <- ssesw / (n - p - 1)
yhat <- if(p == 0) mean(y) else fitted(lm(y ~ z[, xvars]))
}
f <- lm(y ~ x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8)
if(method == 'stepaic') {
g <- stepAIC(f, trace=0)
p <- g$rank - 1
xs <- if(p == 0) 'none' else
gsub('[ <br>+x]','', as.character(formula(g))[3])
if(pr) print(formula(g), showEnv=FALSE)
ssesw <- sum(resid(g)^2)
s2s <- ssesw/g$df.residual
yhat <- fitted(g)
}
# Set SSEsw / (n - gdf - 1) = true sigma^2
gdf <- n - 1 - ssesw / (sigma^2)
# Compute root mean squared error against true linear predictor
rmse.full <- sqrt(mean((fitted(f) - lp) ^ 2))
rmse.step <- sqrt(mean((yhat - lp) ^ 2))
list(stats=c(n=n, vratio=s2s/(sigma^2),
gdf=gdf, apparentdf=p, rmse.full=rmse.full, rmse.step=rmse.step),
xselected=xs)
}
rsim <- function(B, n, method=c('stepaic', 'leaps')) {
method <- match.arg(method)
xs <- character(B)
r <- matrix(NA, nrow=B, ncol=6)
for(i in 1:B) {
w <- sim(n, method=method)
r[i,] <- w$stats
xs[i] <- w$xselected
}
colnames(r) <- names(w$stats)
s <- apply(r, 2, median)
p <- r[, 'apparentdf']
s['apparentdf'] <- mean(p)
print(round(s, 2))
print(table(p))
cat('Prob[correct model]=', round(sum(xs == '1237')/B, 2), '\n')
}Show the correlation matrix being assumed for the \(X\)s:
uncorrelated <- TRUE
sim(50000, prcor=TRUE) x1 x2 x3 x4 x5 x6 x7 x8
x1 1.00 0.00 -0.01 0.00 0.01 0.01 0.00 0.01
x2 0.00 1.00 0.00 0.00 0.01 0.00 0.00 0.00
x3 -0.01 0.00 1.00 0.00 0.00 0.00 0.00 -0.01
x4 0.00 0.00 0.00 1.00 0.01 0.00 0.00 0.01
x5 0.01 0.01 0.00 0.01 1.00 0.01 0.00 0.00
x6 0.01 0.00 0.00 0.00 0.01 1.00 0.00 0.00
x7 0.00 0.00 0.00 0.00 0.00 0.00 1.00 0.01
x8 0.01 0.00 -0.01 0.01 0.00 0.00 0.01 1.00Simulate to find the distribution of the number of variables selected, the proportion of simulations in which the true model (\(X_{1}, X_{2}, X_{3}, X_{7}\)) was found, the median value of \(\hat{\sigma}^{2}/\sigma^{2}\), the median effective d.f., and the mean number of apparent d.f., for varying sample sizes.
set.seed(11)
m <- 'leaps' # all possible regressions stopping on R2adj
rsim(100, 20, method=m) # actual model found twice out of 100 n vratio gdf apparentdf rmse.full rmse.step
20.00 0.94 5.32 4.10 1.62 1.58
p
1 2 3 4 5 6 7 8
3 14 18 22 27 11 4 1
Prob[correct model]= 0.02 rsim(100, 40, method=m) n vratio gdf apparentdf rmse.full rmse.step
40.00 0.61 17.89 4.38 1.21 1.24
p
2 3 4 5 6 7
9 18 24 29 15 5
Prob[correct model]= 0.04 rsim(100, 150, method=m) n vratio gdf apparentdf rmse.full rmse.step
150.00 0.44 85.99 5.01 0.59 0.57
p
2 3 4 5 6 7 8
1 5 27 35 24 7 1
Prob[correct model]= 0.2 rsim(100, 300, method=m) n vratio gdf apparentdf rmse.full rmse.step
300.00 0.42 177.01 5.16 0.43 0.40
p
4 5 6 7 8
27 42 20 10 1
Prob[correct model]= 0.26 rsim(100, 2000) n vratio gdf apparentdf rmse.full rmse.step
2000.00 1.00 6.43 4.58 0.17 0.15
p
4 5 6 7
53 37 9 1
Prob[correct model]= 0.53 As \(n\uparrow\) the mean number of variables selected increased. The proportion of simulations in which the correct model was found increased from 0 to 0.53. \(\sigma^{2}\) is underestimated when \(n=300\) by a factor of 0.42, resulting in the d.f. needed to de-bias \(\hat{\sigma^{2}}\) being greater than \(n\) when the apparent d.f. was only 5.16 on the average. Variable selection slightly increased closeness to the true \(X\beta\).
If the simulations are re-run allowing for collinearities (uncorrelated=FALSE) one can expect variable selection to be even more problematic.
Variable selection methods (Harrell, 1986):
See also these articles:
Some of the information in the data is spent on variable selection instead of using all information for estimation.
Model specification is preferred to model selection.
Information content of the data usually insufficient for reliable variable selection.
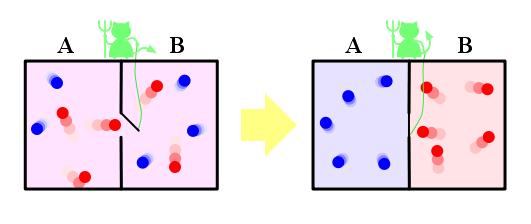

Maxwell imagines one container divided into two parts, A and B. Both parts are filled with the same gas at equal temperatures and placed next to each other. Observing the molecules on both sides, an imaginary demon guards a trapdoor between the two parts. When a faster-than-average molecule from A flies towards the trapdoor, the demon opens it, and the molecule will fly from A to B. Likewise, when a slower-than-average molecule from B flies towards the trapdoor, the demon will let it pass from B to A. The average speed of the molecules in B will have increased while in A they will have slowed down on average. Since average molecular speed corresponds to temperature, the temperature decreases in A and increases in B, contrary to the second law of thermodynamics.
Szilárd pointed out that a real-life Maxwell’s demon would need to have some means of measuring molecular speed, and that the act of acquiring information would require an expenditure of energy. Since the demon and the gas are interacting, we must consider the total entropy of the gas and the demon combined. The expenditure of energy by the demon will cause an increase in the entropy of the demon, which will be larger than the lowering of the entropy of the gas.
Source: commons.wikimedia.org/wiki/File:YoungJamesClerkMaxwell.jpg
en.wikipedia.org/wiki/Maxwell’s_demon
Peter Ellis’ blog article contains excellent examples of issues discussed here but applied to time series modeling.
3 The sample size needed for these is model-dependent
| Type of Response Variable | Limiting Sample Size \(m\) |
|---|---|
| Continuous | \(n\) (total sample size) |
| Binary | \(3nq(1-q), q=\frac{n_{2}}{n}\) 4 |
| Ordinal (\(k\) categories) | \(n - \frac{1}{n^{2}} \sum_{i=1}^{k} n_{i}^{3}\) 5 |
| Failure (survival) time | number of failures 6 |
4 If one considers the power of a two-sample binomial test compared with a Wilcoxon test if the response could be made continuous and the proportional odds assumption holds, the effective sample size for a binary response is \(3 n_{1}n_{2}/n \approx 3 \min(n_{1}, n_{2})\) if \(\frac{n_{1}}{n}\) is near 0 or 1 (Whitehead, 1993, Eq. 10, 15). Here \(n_{1}\) and \(n_{2}\) are the marginal frequencies of the two response levels (Peduzzi et al., 1996). The effective sample size is a maximum (\(0.75n\)) when \(n_{1}=n_{2}\), i.e. \(q=\frac{1}{2}\) .
5 Based on the power of a proportional odds model two-sample test when the marginal cell sizes for the response are \(n_{1}, \ldots, n_{k}\), compared with all cell sizes equal to unity (response is continuous) (Whitehead, 1993, Eq. 3). If all cell sizes are equal, the relative efficiency of having \(k\) response categories compared to a continuous response is \(1 - \frac{1}{k^{2}}\) (Whitehead, 1993, Eq. 14), e.g., a 5-level response is almost as efficient as a continuous one if proportional odds holds across category cutoffs.
6 This is approximate, as the effective sample size may sometimes be boosted somewhat by censored observations, especially for non-proportional hazards methods such as Wilcoxon-type tests (BENEDETTI et al., 1982).
To derive the effective sample size for binary \(Y\) we compare two samples of equal size \(\frac{n}{2}\) by testing whether the log odds ratio is zero. When the two samples come from populations with equal \(\Pr(Y=1) = q\), the variance of the log odds ratio is approximately \(2 \times \frac{1}{\frac{n}{2}q(1-q)} = \frac{4}{nq(1-q)}\). When \(Y\) is continuous with no ties and a Wilcoxon or proportional odds model test is used, the reciprocal of the variance of the proportional odds model’s log odds ratio is \(\frac{n^{3}}{12 (n+1)^{2}} \times (1 - \frac{1}{n^{2}}) \approx \frac{n}{12}\) so the variance is approximately \(\frac{12}{n}\). The ratio of this to the binary \(Y\) variance is \(3q(1-q)\).
![]()
set.seed(123)
n <- 50
y <- runif(20*n)
group <- rep(1:20,each=n)
ybar <- tapply(y, group, mean)
ybar <- sort(ybar)
plot(1:20, ybar, type='n', axes=FALSE, ylim=c(.3,.7),
xlab='Group', ylab='Group Mean')
lines(1:20, ybar)
points(1:20, ybar, pch=20, cex=.5)
axis(2)
axis(1, at=1:20, labels=FALSE)
for(j in 1:20) axis(1, at=j, labels=names(ybar)[j])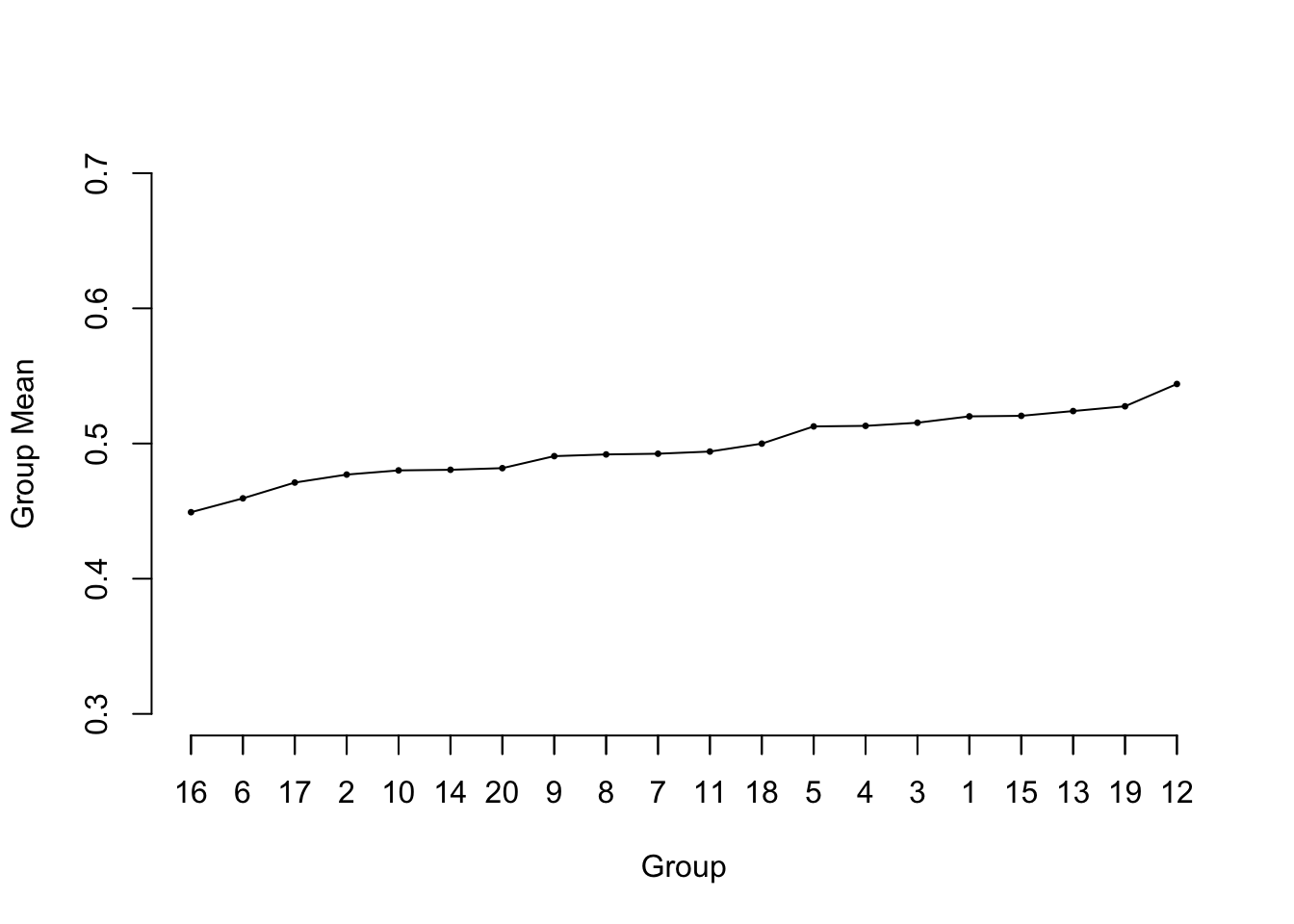
Prevent shrinkage by using pre-shrinkage
Spiegelhalter (1986): var. selection arbitrary, better prediction usually results from fitting all candidate variables and using shrinkage
Shrinkage closer to that expected from full model fit than based on number of significant variables (Copas, 1983)
Ridge regression (le Cessie & van Houwelingen, 1992; van Houwelingen & le Cessie, 1990)
Penalized MLE (Gray, 1992; Harrell et al., 1998; Verweij & van Houwelingen, 1994)
Heuristic shrinkage parameter of van Houwelingen and le Cessie (van Houwelingen & le Cessie, 1990, Eq. 77) \[\hat{\gamma} = \frac{{\rm model}\ \chi^{2} - p}{{\rm model}\ \chi^{2}}, \tag{4.1}\]
OLS7: \(\hat{\gamma} = \frac{n-p-1}{n-1} R^{2}_{\rm adj} / R^{2}\)
\(R^{2}_{\rm adj} = 1 - (1 - R^{2})\frac{n-1}{n-p-1}\)
\(p\) close to no. candidate variables
Copas (1983) (Eq. 8.5) adds 2 to numerator
VARCLUS procedure (Sarle, 1990), R varclus function, other clustering techniques: group highly correlated variablesR function redun in Hmisc packageExample: Figure 15.6
Reduce \(p\) by estimating transformations using associations with other predictors
Purely categorical predictors – correspondence analysis (Ciampi et al., 1986; Crichton & Hinde, 1989; Greenacre, 1988; Leclerc et al., 1988; Michailidis & de Leeuw, 1998)
Mixture of qualitative and continuous variables: qualitative principal components
Maximum total variance (MTV) of Young, Takane, de Leeuw (Michailidis & de Leeuw, 1998; Young et al., 1978)
Maximum generalized variance (MGV) method of Sarle (Kuhfeld, 2009, pp. 1267–1268)
MTV (PC-based instead of canonical var.) and MGV implemented in SAS PROC PRINQUAL (Kuhfeld, 2009)
R transcan Function for Data Reduction & Imputation
Initialize missings to medians (or most frequent category)
Initialize transformations to original variables
Take each variable in turn as \(Y\)
Exclude obs. missing on \(Y\)
Expand \(Y\) (spline or dummy variables)
Score (transform \(Y\)) using first canonical variate
Missing \(Y\) \(\rightarrow\) predict canonical variate from \(X\)s
The imputed values can optionally be shrunk to avoid overfitting for small \(n\) or large \(p\)
Constrain imputed values to be in range of non-imputed ones
Imputations on original scale
Multiple imputation — bootstrap or approx. Bayesian bootstrap.
fit.mult.impute works with aregImpute and transcan output to easily get imputation-corrected variances and avg. \(\hat{\beta}\)Option to insert constants as imputed values (ignored during transformation estimation); helpful when a lab value may be missing because the patient returned to normal
Imputations and transformed values may be easily obtained for new data
An R function Function will create a series of R functions that transform each predictor
Example: \(n=415\) acutely ill patients
require(Hmisc)
getHdata(support) # Get data frame from web site
heart.rate <- support$hrt
blood.pressure <- support$meanbp
blood.pressure[400:401]Mean Arterial Blood Pressure Day 3
[1] 151 136blood.pressure[400:401] <- NA # Create two missings
d <- data.frame(heart.rate, blood.pressure)
w <- transcan(~ heart.rate + blood.pressure, transformed=TRUE,
imputed=TRUE, show.na=TRUE, data=d, trantab=TRUE, pl=FALSE)Convergence criterion:2.901 0.035 0.007
Convergence in 4 iterations
R-squared achieved in predicting each variable:
heart.rate blood.pressure
0.259 0.259
Adjusted R-squared:
heart.rate blood.pressure
0.254 0.253 ggplot(w)
w$imputed$blood.pressure 400 401
132.4057 109.7741 t <- w$transformed
spe <- round(c(spearman(heart.rate, blood.pressure),
spearman(t[,'heart.rate'],
t[,'blood.pressure'])), 2)transcan. Tick marks indicate the two imputed values for blood pressure.
spar(mfrow=c(1,2))
plot(heart.rate, blood.pressure)
plot(t[,'heart.rate'], t[,'blood.pressure'],
xlab='Transformed hr', ylab='Transformed bp')ACE (Alternating Conditional Expectation) of Breiman & Friedman (1985)
These methods find marginal transformations
Check adequacy of transformations using \(Y\)
Series of dichotomous variables:
Using Expected Shrinkage to Guide Data Reduction
Example:
| Goals | Reasons | Methods |
|---|---|---|
| Group predictors so that each group represents a single dimension that can be summarized with a single score | • \(\downarrow\) d.f. arising from multiple predictors • Make \(PC_1\) more reasonable summary |
Variable clustering • Subject matter knowledge • Group predictors to maximize proportion of variance explained by \(PC_1\) of each group • Hierarchical clustering using a matrix of similarity measures between predictors |
| Transform predictors | • \(\downarrow\) d.f. due to nonlinear and dummy variable components • Allows predictors to be optimally combined • Make \(PC_1\) more reasonable summary • Use in customized model for imputing missing values on each predictor |
• Maximum total variance on a group of related predictors • Canonical variates on the total set of predictors |
Reasons for influence:
Statistical Measures:
See also Section 5.6
Greenland (2000) discusses many important points:
Greenland’s example of inadequate adjustment for confounders as a result of using a bad modeling strategy:
Global Strategies
Preferred Strategy in a Nutshell
For an excellent tutorial covering many strategical aspects of developing and validating predictive models see Efthimiou et al. (2024).
Section 4.1
Section 4.3
Section 4.4
Section 4.5
Section 4.6
Section 4.7
Section 4.9
Section 4.10
Section 4.12
{kind=link}